

Robert Williams had just pulled into his Farmington Hills driveway after another long day’s work, relieved to finally spend time with his wife and two daughters. Nothing seemed obviously amiss.
But something was very wrong. A police car waiting down the street inched forward, trapping Williams against his own house. Two officers approached, cuffing him in front of his family as they cried out in bewilderment and distress. Williams’ wife’s pleas to learn where he was being taken went unanswered, though one of the officers snarkily replied, “Google it.”
Williams was driven to a nearby detention center, where law enforcement took his mugshot, fingerprints, and DNA. He was held overnight, interrogated by two detectives, and assigned a court date. But, once in court, prosecutors dropped the charges. His arrest, they admitted, was based on “insufficient evidence.”
Later, state police revealed their “insufficient evidence” was the product of a facial recognition machine learning algorithm. It had analyzed grainy video footage from a robbed Detroit retail store and determined that Williams was the offender, even though Williams recalled he looked nothing like the actual robber.
Williams’ false arrest may be the first of its kind, but it won’t be the last. One in four law enforcement agencies have unregulated access to facial-recognition software, and more than half of Americans are in police facial-recognition databases. It also isn’t surprising that Williams—a Black man—was the first case; according to the National Institute of Standards and Technology, a majority of facial-recognition software is racially biased.
Code Isn’t the Problem
To be fair to the Michigan police who arrested Williams, it seems outlandish that machine learning could be racist.
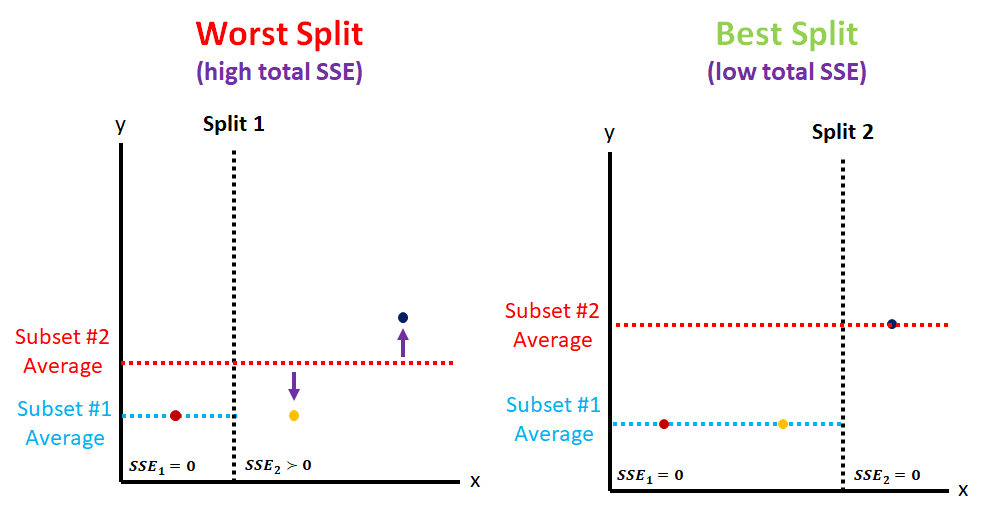
Machine learning algorithms are just lines of computer code that minimize error between values in a dataset—called training data—to generate predictive models. Error is calculated however the coder wants it to be and the code runs until error reaches zero or the coder instructs it to stop.
For instance, one form of error used in machine learning algorithms is the difference between a value and an average value. This allows programmers to quantify the error of entire datasets. For every value in a dataset, error can be squared and summed with the other errors, producing a sum of squared errors (SSE).
Some machine learning algorithms minimize dataset error by forming smaller subsets and recalculating the SSE for each. Adding the resulting SSEs allows the algorithm to generate a total SSE unique to each split. The split that produces the smallest total SSE is considered the best and is recorded for later.
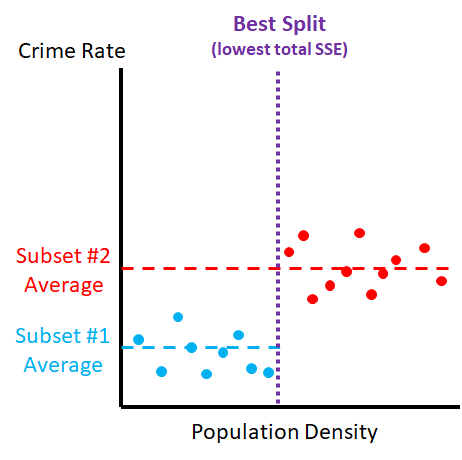
Imagine using a machine learning model to analyze this dataset describing crime in North Carolina. One of the variables included is population density. If a machine learning algorithm was fed this information, it would split the data into different groups for every density value until it found the split that minimized the total SSE.
But the dataset includes other variables, such as year, probability of arrest, and police officers per capita. Machine learning algorithms account for the different variables in training data by minimizing the total SSE for each one, then selecting the best split out of all the variables.
The algorithm repeatedly forms subsets and splits the data within each one until error reaches zero or a set end point. The best splits are organized into a model that can be fed new data to predict outcomes. Below is a sample decision tree—one type of predictive model—that could be generated from the North Carolina crime dataset to predict crime rates:
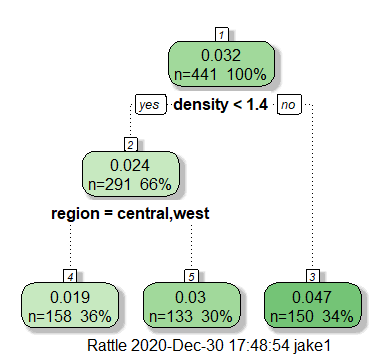
All these complex calculations designed to minimize error and predict outcomes have no obvious racist influences; machine learning algorithms themselves can’t discriminate. However, the data that programmers feed to algorithms can train them to.
The Data Dilemma
Machine learning models have no ethical code. If predicting an outcome by race minimizes error and improves predictive accuracy, the algorithm will do it. The same is true when predicting by sex, religion, nose length, or any characteristic.
In practice, this means that demographically skewed datasets can train discriminatory algorithms. It doesn’t matter whether machine learning is used for facial recognition or medical diagnosis—biased training data creates biased models.
For instance, imagine a Boston-based technology company, Boston SuperTech, using machine learning algorithms for hiring. They use a database of employees’ demographic information, ratings of their old résumés, and their time spent at the company to train a basic Categorization and Regression Tree (CART) model (source code here). Then they leverage the CART to predict which incoming job applicants are likely to spend at least ten years at the company.
None of this sounds unreasonable on its face. Maybe staying at the company appeals to some groups of people more than others or people with stronger résumés are more likely to climb the corporate ladder.
But this is what the CART model would look like:
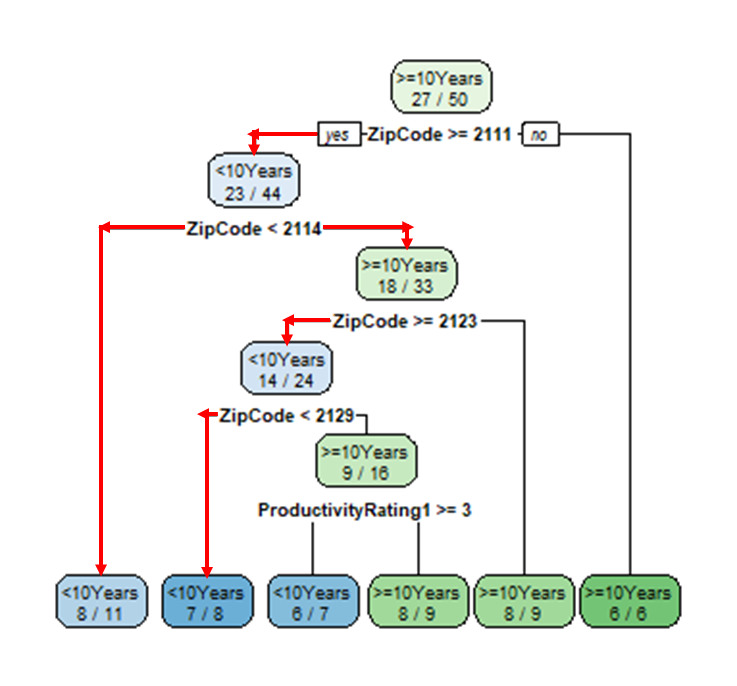
If Boston SuperTech applied this algorithm in hiring, nearly every minority applicant would be turned away. The model racially discriminates by using ZIP code as a stand-in for race. ZIP codes 02124, 02125, and 02111 are the only majority-minority districts represented in Boston SuperTech’s employee database. Applicants from all of them would be classified as unlikely long-term hires by the CART model.
Minorities have been underrepresented among computer science majors for over two decades, so most of Boston SuperTech’s previous long-term hires were White. When Boston SuperTech gave the CART algorithm their training data, the algorithm took advantage of the indirect association between race and corporate loyalty to improve predictive accuracy.
Just like the real case of Robert Williams, machine learning in this example translated neutral intentions into blatantly unjust outcomes. Seemingly reasonable corporate practices—like using machine learning to predict corporate loyalty—can embed discrimination in hiring.
Finding Discriminatory Algorithms Is Hard
In this hypothetical, Boston SuperTech could generate a visual output of their CART model and discover that it uses ZIP code as a proxy for race. However, scientists can’t visualize most machine learning models as easily.
More advanced modeling methods, like random forests (RF), are more accurate than simplistic CART-like models but are much less interpretable.
Random forests predict outputs by aggregating hundreds to thousands of individual decision trees’ predictions to generate a “forest” of trees. But this makes it extremely difficult to understand why a random forest predicts the way it does. Above, I’ve pictured one decision tree, and even that is somewhat difficult to follow. One random forest can generate thousands of those diagrams, each with its own set of rules. And random forest decision trees are generated differently than CARTs, making them orders of magnitude more complex.
To figure out if a random forest is discriminating the same way Boston SuperTech did for their CART model, a scientist would need to follow many rules and outputs for thousands of individual trees. It’s simply not feasible.
So scientists generate databases designed to test algorithm fairness, then run them through allegedly discriminatory models. If outputs differ from expected non-discriminatory results, then a model is probably discriminating. But creating a database and accessing a company’s modeling software aren’t easy.
As a result, it has taken scientists months or years to root out discriminatory hiring, ad delivery, recidivism prediction, loan distribution, and facial-recognition models created by Amazon, Facebook, Northpointe, mortgage lenders, and Twitter and Google, respectively. This difficulty is also why scientists will probably never know just how many discriminatory algorithms are out there. More than half of hiring managers and recruiters report that artificial intelligence (a broad term used to describe machine learning concepts) is helpful in sourcing and screening job candidates. Yet the effort needed to uncover bias means that only a fraction of companies’ algorithms will be investigated.
The Data Dilemma Part Two: A Mini Experiment
To demonstrate the ease with which machine learning can discriminate, I created a facial recognition random forest model of my own (source code here) and tested it with images of White and Black faces.
My model identifies faces by reading the spatial distribution of color across an image and comparing it to images I’ve told it are faces. If the color distributions of a new image are similar enough to one it already knows is a face, then it predicts that the new image is a face as well.
For the purposes of this experiment, I trained my model only on White faces. Because White and Black faces have different color distributions, I hypothesized that my model would recognize new White faces more often than it would recognize new Black faces.
As expected, when I exposed my model to fifteen new White faces and fifteen new Black faces, it recognized 87 percent of the White faces, but only 33 percent of the Black faces. A chi-squared test confirmed that facial recognition by my model depends on race (p=0.003).
Of course, in the real world, facial recognition models aren’t trained just on White faces. However, any disparity in the racial makeup of training data could result in discrimination, even slight disparities that aren’t obvious to the human eye. If my model were more accurate, it would recognize faces according to smaller differences in skin tone. These more detailed predictions would be more difficult to test for discrimination; testing databases would need to include many more than thirty images and each image set would need to be categorized by more specific criteria.
Regardless, my experiment shows that, though the code in machine learning models may not be biased, if they are trained on the wrong dataset, their predictions will be.
Machine Learning in Moderation
Machine learning is extraordinarily useful. It can be applied in all manner of scientific research, from ecological surveys to biological protein modeling. Doing away with it entirely would be disastrous.
But in many social, political, and economic contexts, machine learning just isn’t the right tool to use. Its very nature is to decide outcomes according to broad group trends in whatever time period its training data is from.
For instance, if a machine learning model were created in 1970 to help colleges admit biology majors using data from the past five years, it would probably recommend they admit mostly men. If an identical model were created in 2008, it would probably recommend they admit mostly women. This is because between 1965 and 1970, approximately 30 percent of biology majors were women, while between 2003 and 2008, about 60 percent were.
And blatant bigotry pervades many historical group trends. Facebook’s discriminatory ad delivery program learned to show “home for sale” ads to White users because minorities were less likely to engage these types of ads, but this pattern of behavior can be traced back to slavery, redlining, and discriminatory lending. These practices stymied minority wealth accumulation, reducing their home-buying potential today.
Outside of scientific research, machine learning should be applied sparingly. Corporations and government agencies must be required by law to prove that their algorithms do not discriminate, or else be forbidden from using them at all. And even when implemented, institutions should interpret model outputs in the context of other data before making decisions.
For now, people are better decision-makers than algorithms.

